Diego, CTO de uma fintech em Belo Horizonte, aprovou o projeto em março. Em agosto, o agente de IA estava em produção — mas respondia errado 30% das vezes. Ele culpou o modelo por três semanas. Testou GPT-4o, Claude Sonnet, Gemini — os três com resultado similar. Antes de desistir, um engenheiro sênior pediu para inspecionar a base de dados de clientes que alimentava o contexto do agente. O que encontrou: quatro formatos diferentes de CPF no mesmo campo, dois campos de "status de conta" com nomenclaturas conflitantes criadas por times diferentes ao longo de cinco anos, e nenhum dicionário de dados explicando o que cada coluna realmente significava. O modelo estava correto. Os dados estavam errados. Diego tinha passado três meses e R$ 180 mil tentando resolver um problema de dados com uma solução de modelo.
Esse padrão não é exceção. É a regra. E os dados de mercado confirmam com precisão perturbadora o que CTOs e Tech Leads estão vivendo nos bastidores.
Os 7 Erros Fatais que PMEs
Cometem ao Adotar IA
Levantamento com dados reais do Cetic.br, IBGE, Microsoft e OCDE.
Sem custo. Cadastro com e-mail para receber o material.
- ✓ Dossiê V1 imediato após confirmação de email
- ✓ Link exclusivo de indicação
- ✓ Dossiê V2 ao indicar 3 pessoas
Leitura de ~12 min · sem spam
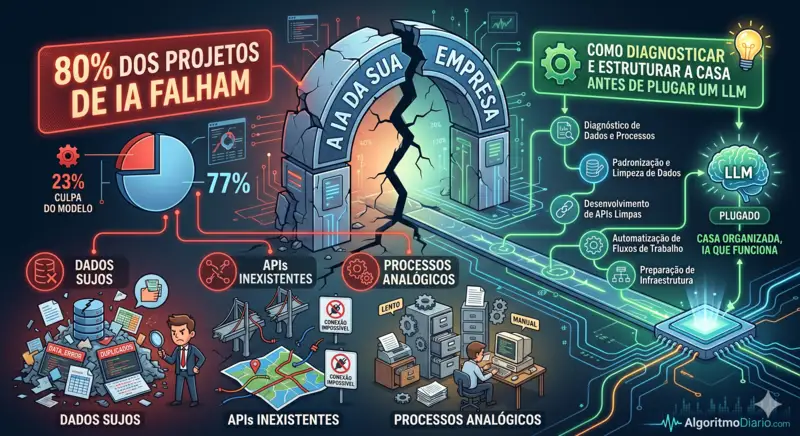
O padrão que se repete: piloto funciona, produção quebra
Análise de 140 implementações enterprise mostrou que apenas 23% das falhas foram causadas por desempenho do modelo ou complexidade de integração técnica. Os outros 77% vieram de estratégia, governança e gestão da mudança — com dados de má qualidade como causa raiz mais frequente. A Gartner estimou que apenas 12% das organizações têm dados de qualidade suficiente para suportar aplicações de IA em produção, e previu que 60% dos projetos sem dados AI-ready seriam abandonados ao longo de 2026. Esse calendário está se cumprindo.
A pergunta que CTOs deveriam fazer antes de contratar qualquer API de LLM não é "qual modelo usar". É: o que esse modelo vai consumir? E a resposta honesta, na maioria das empresas brasileiras de médio porte, é: um conjunto de dados construído ao longo de anos sem nenhuma preocupação com padronização, porque nunca havia uma máquina que fosse lê-los de verdade.
Onde a falha realmente mora: os 4 problemas estruturais
Depois de anos de promessas de transformação digital, a maioria das empresas acumulou uma dívida técnica específica que a IA torna imediatamente visível. São quatro problemas estruturais que se repetem independentemente do setor, do tamanho da empresa e do modelo de LLM escolhido.
| Problema | Como aparece na IA | Frequência | Custo de ignorar |
|---|---|---|---|
| Dados sem padronização | Modelo produz outputs inconsistentes para inputs semanticamente iguais | Crítico | Projeto abandonado em produção |
| APIs inexistentes ou quebradas | Agente não consegue executar ações — só descreve o que faria | Crítico | Agente vira chatbot glorificado |
| Documentação caótica ou ausente | Modelo alucina para preencher lacunas de contexto | Muito alto | Respostas erradas com aparência certa |
| Processos analógicos não mapeados | IA automatiza o passo errado ou o passo que deveria ser eliminado | Alto | Automação do caos — mais rápido, mesmo resultado |
Dados sujos — o assassino silencioso de projetos de IA
Um modelo de linguagem não sabe que CPF: 123.456.789-00 e CPF: 12345678900 representam a mesma pessoa. Ele trata como duas entidades distintas. Quando o seu pipeline de RAG (Retrieval Augmented Generation) busca contexto sobre um cliente e encontra dois registros conflitantes, ele não escolhe o correto — ele tenta reconciliar, e frequentemente inventa uma resposta coerente que é factualmente errada. Isso não é bug do modelo. É o modelo fazendo exatamente o que foi projetado para fazer: produzir texto coerente com o contexto fornecido. O contexto é que está errado.
Os problemas mais comuns em bases de dados de empresas brasileiras de médio porte, na ordem em que mais destroem projetos de IA:
✗ Problema #1 — Inconsistência de formato
Mesmo dado, múltiplos formatos
CPF com e sem máscara no mesmo campo. Datas em DD/MM/AAAA e AAAA-MM-DD na mesma coluna. Status como "ativo", "Ativo", "ATIVO" e "1" representando a mesma coisa. O modelo trata todos como diferentes.
✓ Solução
Pipeline de normalização antes do modelo
Antes de qualquer chamada de API, normalize: CPF sempre sem máscara, datas sempre ISO 8601, status sempre lowercase. Isso é um script de 50 linhas que salva o projeto.
✗ Problema #2 — Campos críticos em branco
Nulos onde o modelo espera contexto
30% dos registros com categoria_produto em branco. O modelo não sabe dizer "não tenho essa informação" — ele infere, e infere errado. Campos nulos viram alucinações disfarçadas de contexto.
✓ Solução
Auditoria de cobertura antes do go-live
Calcule a cobertura de cada campo que o modelo vai consumir. Abaixo de 85% de preenchimento em campos críticos: pare o projeto e corrija a origem. Não dá para treinar o modelo a adivinhar o que não existe.
SELECT DISTINCT status FROM clientes retornando 7 valores), você tem um problema de padronização que o modelo vai amplificar, não resolver.
APIs inexistentes e integrações quebradas
Um agente de IA que não consegue executar ações é um chatbot caro. A grande promessa dos agentes de 2026 — que eles possam não apenas responder perguntas mas executar tarefas — depende de um pressuposto que a maioria das empresas não satisfaz: que os sistemas internos exponham APIs limpas e documentadas para o agente consumir.
Na realidade brasileira de médio porte, o que existe é: um ERP de 2015 sem API REST, um CRM com webhook que funciona "às vezes", um sistema de estoque que só exporta Excel e um sistema de cobrança acessível apenas via interface web. Para um agente de IA executar uma ação nesse ecossistema, alguém precisa primeiro construir a camada de integração — e esse trabalho raramente aparece no escopo original do projeto.
O resultado é o que Neuwark Research chamou em 2026 de "agente de fachada": um LLM que descreve o que faria se pudesse executar a ação, mas que na prática gera um rascunho para um humano executar manualmente. Tecnicamente impressionante na demo. Operacionalmente inútil em produção.
# Antes de definir as ferramentas (tools) do agente,
# mapeie cada ação para o endpoint real:
AÇÃO: "consultar status do pedido"
→ GET /api/pedidos/{id}/status ✅ existe
→ Documentado? Sim | Auth? Bearer token ✅
AÇÃO: "atualizar endereço do cliente"
→ PATCH /api/clientes/{id} ⚠️ existe, mas não testado
→ Documentado? Incompleto | Quem mantém? Time desconhecido
AÇÃO: "emitir nota fiscal"
→ Sem API. Só via tela do ERP ❌ bloqueante
→ Solução: construir wrapper antes de prosseguir
# Regra: se mais de 2 ações críticas não têm endpoint,
# pause o projeto de agente e abra sprint de APIs primeiro.
Documentação caótica: o problema que ninguém confessa
Existe uma categoria de problema que raramente aparece em post-mortems de projetos de IA porque ninguém quer admitir: a documentação interna é um desastre. Regras de negócio que só existem na cabeça de um analista que saiu em 2023. Fluxos de aprovação que "todo mundo sabe como funciona" mas ninguém escreveu. Campos de banco de dados com nomes crípticos que faziam sentido quando foram criados mas cujo significado atual é ambíguo até para o time que os usa diariamente.
Quando um agente de IA recebe contexto insuficiente, ele não retorna um erro — ele alucina uma resposta coerente. E o problema específico de alucinações em contexto de negócio é que elas frequentemente parecem corretas para quem lê sem conhecimento profundo do domínio. Um agente que alucina regras de negócio cria uma confiança falsa que é mais perigosa do que um erro óbvio.
A solução não é "treinar o modelo a não alucinar" — isso não funciona. A solução é eliminar as lacunas de contexto que forçam o modelo a alucinação. Isso significa documentar antes de plugar a IA:
| O que documentar | Formato recomendado | Por que importa para IA |
|---|---|---|
| Dicionário de dados | Markdown — campo, tipo, regra de negócio, exemplo | O modelo precisa entender o que cada campo significa para não inventar |
| Regras de negócio críticas | Fluxo com condições explícitas (se X então Y) | Regras implícitas viram alucinação — o modelo faz a lógica que parece razoável |
| Casos extremos e exceções | Lista de "nunca faça X", "se Y, sempre verifique Z" | Exceções são onde agentes erram com mais confiança e menos sinalização |
| Glossário de termos internos | Termo → definição precisa no contexto da empresa | "Cliente ativo" pode significar 5 coisas diferentes em 5 sistemas diferentes |
Como estruturar a casa antes de plugar o LLM
A sequência correta não é "escolha o modelo → integre os dados → ajuste os prompts". É o inverso. O modelo é a última decisão, não a primeira. A sequência que funciona:
1. Mapeie o processo que vai automatizar — completamente. Documente cada passo, cada decisão, cada exceção. Se o processo ainda não está documentado e funcionando bem de forma manual, automatizá-lo com IA vai apenas tornar o caos mais rápido. Automatize processos que funcionam — não processos que precisam ser corrigidos.
2. Audite os dados que o modelo vai consumir. Para cada campo crítico: qual a cobertura de preenchimento? Quais são os valores distintos? Há inconsistências de formato? Esse trabalho custa entre 1 e 3 sprints. Pular custa o projeto inteiro.
3. Mapeie as ações que o agente precisa executar e confirme que os endpoints existem. Se faltam APIs, abra o escopo de desenvolvimento antes de abrir o escopo de IA. Um agente sem ferramentas funcionais é um chatbot com prompts complexos.
4. Escreva o dicionário de dados e as regras de negócio em linguagem natural. Esse documento vai diretamente para o system prompt do agente — é o que elimina as lacunas de contexto que causam alucinação.
5. Só então: escolha o modelo, escreva os prompts, integre. Nessa ordem. Com essa base, o modelo — qualquer modelo de qualidade atual — vai performar bem. Sem essa base, nem o melhor modelo resolve.
Checklist de AI-readiness para times técnicos
🔴 Dados — bloqueante se não atendido
- Campos críticos têm cobertura de preenchimento acima de 85%
- Campos categóricos têm vocabulário controlado e documentado
- Formatos padronizados: datas ISO 8601, CPF/CNPJ sem máscara, status lowercase
- Ausência de duplicatas em chaves primárias dos registros que o modelo vai consumir
- Pipeline de normalização definido antes da chamada de API do LLM
🟡 Integrações — necessário para agentes reais
- Cada ação que o agente precisa executar tem um endpoint de API mapeado e testado
- Autenticação dos endpoints documentada e funcional em ambiente de produção
- Rate limits e timeouts mapeados — o agente precisa lidar com falhas de integração graciosamente
- Rollback definido para ações críticas (o que acontece se a chamada falhar no meio?)
🟢 Documentação — qualidade do contexto
- Dicionário de dados escrito em linguagem natural para todos os campos consumidos pelo modelo
- Regras de negócio críticas documentadas com condicionais explícitas
- Glossário de termos internos com definições precisas no contexto da empresa
- Lista de casos extremos e exceções que o agente precisa tratar diferente
- Definição clara do que o agente não deve fazer (negative space do escopo)
🟣 Processo — antes de qualquer automação
- O processo que será automatizado está documentado passo a passo
- O processo funciona de forma consistente sem IA — não estamos automatizando algo quebrado
- Métricas de sucesso definidas antes do início (o que "funcionar" significa em números concretos?)
- Protocolo de fallback humano definido — quando e como o agente passa para um humano
🖊️ Na nossa avaliação
A narrativa dominante sobre falha em IA coloca o problema no modelo, no prompt ou na escolha da ferramenta — e essa narrativa beneficia quem vende modelos e ferramentas, não quem precisa entregar resultados. Os dados de 2025–2026 são inequívocos: o problema é pré-modelo em 77% dos casos. A frase mais honesta que um CTO pode dizer ao board antes de aprovar um projeto de IA é: "Antes de contratar qualquer API de LLM, precisamos de um sprint para auditar os dados que esse modelo vai consumir." Isso não é pessimismo. É a única estratégia que tem histórico de funcionar.
📖 Leia também
Perguntas frequentes
Análise de 140 implementações mostrou que apenas 23% das falhas vieram do modelo. Os outros 77% foram estratégia, governança e qualidade de dados. Apenas 12% das organizações têm dados de qualidade suficiente para suportar IA em produção (Gartner, 2025). A IA não cria problemas de dados — ela os expõe com precisão que nenhum sistema anterior tinha.
Dados AI-ready são padronizados, documentados, acessíveis via API ou pipeline limpo e com cobertura suficiente para que o modelo processe sem inventar informações. Características básicas: campos com nomenclatura consistente, ausência de duplicatas críticas, cobertura acima de 85% nos campos relevantes e dicionário de dados documentado. Apenas 7% das empresas dizem que seus dados estão completamente prontos para IA, segundo Cloudera e HBR (2026).
Analistas recomendam 40 a 50% do orçamento total para trabalho de dados — limpeza, padronização, documentação e pipelines de acesso. Isso é contraintuitivo para times que querem ir direto para o modelo, mas é o dado que emerge de análise de 2.400+ iniciativas de IA rastreadas por RAND Corporation. Times que pulam essa etapa chegam à produção mais rápido e abandonam o projeto mais cedo.
Quatro perguntas: (1) Consigo acessar os dados do processo via API ou query limpa em menos de 5 minutos? (2) Tenho documentação explicando o que cada campo significa — não apenas o nome da coluna? (3) Os dados têm cobertura acima de 85% nos campos críticos? (4) O processo que vou automatizar está documentado e funciona de forma consistente sem IA? Resposta 'não' a qualquer uma: resolva antes de plugar qualquer LLM.
No piloto, os dados são curados manualmente pela equipe que conhece o sistema. Em produção, chegam como chegam — com inconsistências e campos vazios que ninguém mapeou. Segundo MIT NANDA Study (2025), 95% dos pilotos de IA generativa não geram retorno mensurável em P&L. A razão: o piloto esconde o problema de dados porque alguém o resolveu na mão para fazer a demo funcionar. Em produção, esse trabalho manual não escala.